嗨,我是小灯。
今天带你
真正搞懂 AI。
从神经网络到 Transformer,从智能体到 Claude Code 实战——一份给高中生的、不劝退的 AI 科普。

第一章 · 深入原理
大模型
到底凭什么
这么聪明?
这一章我们从最底层的「神经元」一路爬到 Transformer,你会看到 AI 的聪明不是魔法,而是一层层结构堆出来的。

一切的开始:
一个会「权衡」的小神经元。
想象你要决定「今天要不要带伞」。你的大脑会同时掂量好几件事:
云多不多
权重 0.5
预报说下雨
权重 0.8
梅雨季
权重 0.3
每个信号乘以它的「权重」加起来 → 超过某个阈值就「带伞」。
这就是一个神经元干的事。
神经元连起来 = 网络
一个神经元太笨,
几百万个连起来就聪明了。
把神经元排成一列列的「层」,前一层的输出喂给下一层。信息就像流水一样,一层层被提炼——从「像素」到「边缘」,从「边缘」到「形状」,最后到「这是一只猫」。
类比 · 流水线工厂
第一层工人只负责看「有没有圆」,第二层看「圆有没有耳朵」,第三层拼成「猫脸」。每层只做简单的事,叠起来却能认出猫。
输入层
原始数据
隐藏层
层层提炼
输出层
给出答案
信息层层提炼:
从一堆像素到「这是一只猫」。
每往下一层,网络就抽象一级——丢掉细节,抓住更整体的特征。
⬜⬜
第 1 层
原始像素
只是颜色点
─ ◯
第 2 层
边缘 / 纹理
线条、轮廓
第 3 层
局部部件
耳朵、眼睛
最后一层
完整概念
「这是猫!」
每层只做简单的事,叠起来却能认出整只猫。
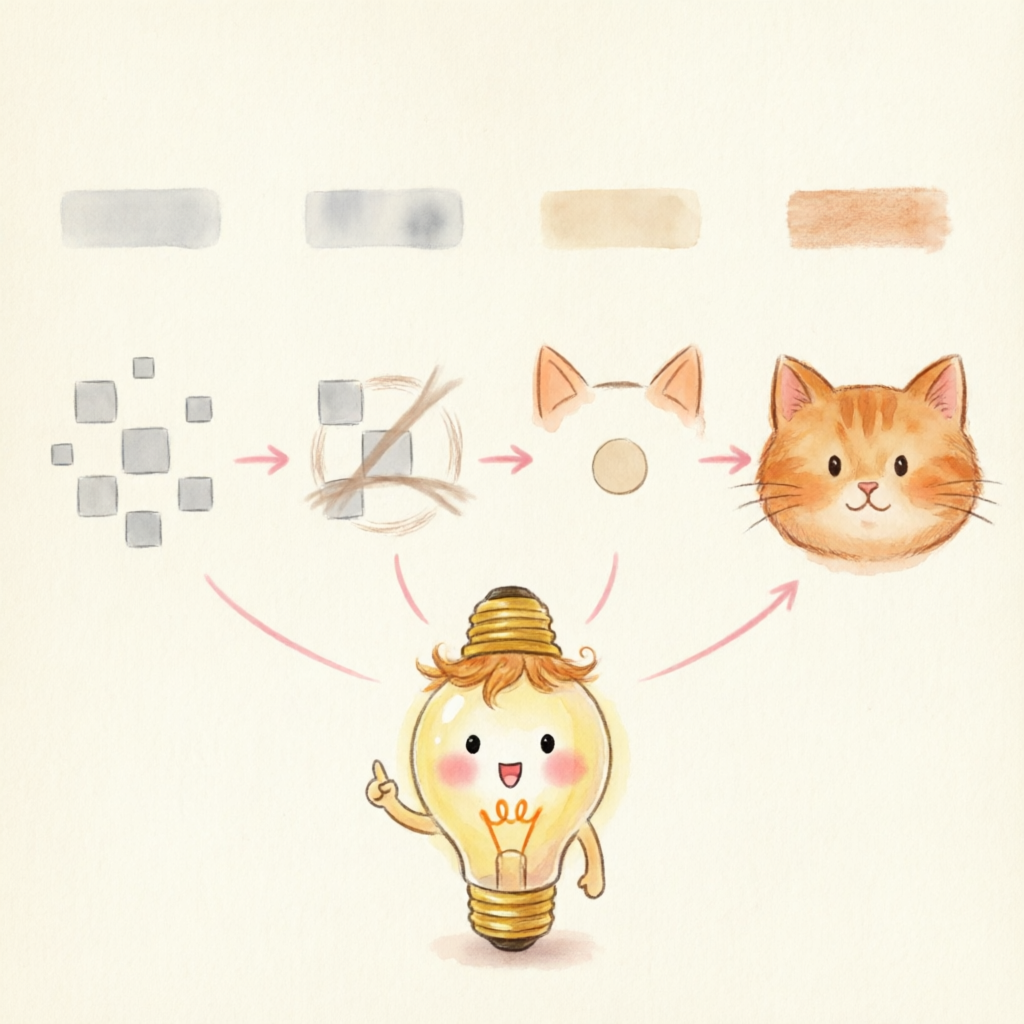
小灯带你看:层越深,看得越「整体」
💡 关键直觉:不是某一层特别聪明,而是分工——浅层管细节,深层管整体。层数越多,能抽象出的概念越高级(这也是下一页「深度学习」的由来)。
但传统网络有个
致命问题……
它「读完就忘」。
处理一句话时,它一个字一个字往后读。读到第 20 个字,第 1 个字的影响已经几乎消失。于是它分不清:
「我昨天看见的那只猫,今天又来了。」
→ 到底是谁来了?「我」还是「猫」?隔了 8 个字,老网络就糊涂了。
语言太依赖远距离的呼应了。我们需要一种能「同时看清全文」的方法——

下一页揭晓它的解法
2017 年,一篇叫《Attention Is All You Need》的论文
Transformer:让 AI 学会
「同时看清整句话」。
类比 · 划重点式阅读
读一句话时,Transformer 不是死板地从左到右,而是让每个字去问所有其他字:「跟我相关的,哪几个最重要?」然后给重要的字画上重点。
「猫追着老鼠跑,最后它抓住了它。」
注意力的连线:黄色↔黄色,绿色↔绿色
「它」指谁?一秒就懂。
新概念 · MoE
既然请不动
所有专家一起看病——
那就按需挂号。
这就是 MoE(Mixture of Experts,专家混合)——现代大模型(如 GLM、DeepSeek)省算力的核心技巧。

现在做大模型的,
主要是这些公司。
国内外都有成熟产品,竞争激烈,对用户是好事——又强又便宜。


第二章 · 智能体登场
只会说的 AI,
升级成会动手的 AI。
大模型是「嘴」,智能体给它装上「眼、手、记忆」。这一章讲清楚 Agent 是什么,以及 Claude Code 怎么成为你的全能助手。
你只要说一句话,
剩下的它来跑。


Skill = 一份说明书,
教 Claude 一种新本事。
你把「怎么做某件事」写成一份 markdown 文件,放进固定目录——它下次遇到这类任务,就会照着做。
本份 PPT 就是这么来的!
我用了 guizang-ppt-skill(瑞士风)和手写卡通版,Claude 读完 skill 文件,就知道该怎么排版、配色、加动效。
MCP = 一根标准插头,
把 AI 接上万物。
MCP(Model Context Protocol,模型上下文协议)是一种统一接口标准——只要工具按这个协议做,任何 AI 都能直接调用,不用每个工具单独对接。
类比 · USB 接口
以前每个设备都有自己的专用插头,现在统一成 USB-C。MCP 之于 AI 工具,就像 USB-C 之于电子设备。

第三章 · 完整实战
从一个想法,
到上线一个真东西。
最后用一个真实例子,带你走完 AI 时代的完整开发流程——你会看到 Claude Code 在每一步都能帮上忙。

THE END · 但只是你的开始
你已入门。
接下来?动手。
装个 Claude Code / Codex / Cursor,真正用它做点东西(哪怕一个待办清单)
去 GitHub 找几个感兴趣的 Skill 装上,看看别人怎么用 AI
把今天学到的原理讲给同学听——能讲清楚,才是真懂了
感谢小灯陪你走完这一程 🌟
AI 第一课 · 给高中生的治愈系科普